Categories
Her data pipeline explained how data helps organizations make informed decisions, enhances operational efficiency, fosters innovation, and supports strategic planning. It also drives growth and competitive advantage in the business environment.
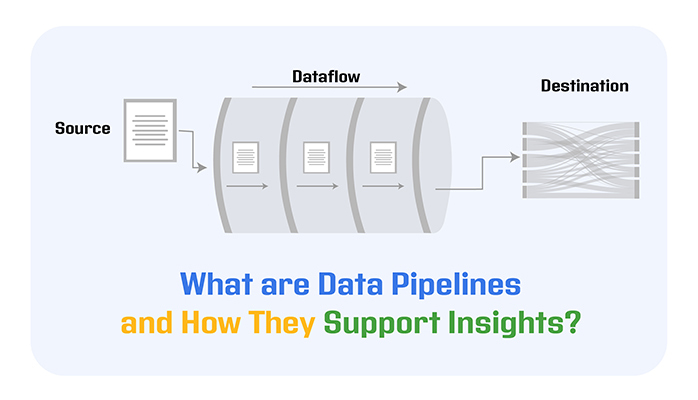



But what are data pipeline basics? Well, this guide shows you what data pipeline meaning are, the importance of data pipelines, and how to build data pipelines.
First…
Definition: A data pipeline is a set of automated processes that collects, moves, and transforms data from different sources to a destination where it can be stored, analyzed, and used for decision-making.
Think of it as a system that ensures your data flows smoothly and accurately, cleaning and organizing it along the way so it’s ready for reporting, analytics, or feeding into business tools. By automating these steps, a data pipeline means is that help organizations save time, maintain data quality, and make insights available faster for smarter decisions.
Nowadays, businesses need real-time data access. With a data pipeline, you’ll get a continuous data flow, which can be visualized using data flow diagrams, helping companies react to market changes and make informed decisions.
Data is as good as its quality and integrity. With a data pipeline, you’ll have clean, consistent, and reliable data. It automates the process of correcting and detecting errors, and that helps maintain the integrity of the data. It also keeps business owners from making misguided decisions.
Insights obtained from data analysis are timely and accurate as the data feeds into the analytical tools. Data pipelines automate data preparation and delivery to these tools, and that ensures that insights generated are based on the most current and well-processed data available.
With a data pipeline, businesses are sure to meet the regulatory standards in their region. Data pipelines also provide a clear and controlled data flow with audit trails and governance controls.
A retail company extracts sales data from its POS systems (Extract), cleans and formats the data (Transform), and loads it into a data warehouse like BigQuery (Load) for weekly sales analysis and reporting.
An e-commerce site captures user clickstream data in real time, streams it through tools like Apache Kafka, and processes it using Spark Streaming to analyze user behavior instantly for personalized product recommendations.
A manufacturing company collects temperature and vibration data from IoT sensors, processes it in real-time, and stores it in a time-series database to monitor machine health and predict maintenance needs.
A marketing team uses a pipeline to extract tweets mentioning their brand, process text for sentiment analysis, and visualize trends in dashboards to track public perception and adjust campaigns.
These pipelines collect and process data in chunks at scheduled intervals (daily, hourly, or weekly). They are ideal for situations where real-time analysis isn’t critical, such as generating daily sales reports or data backups.
Example: Importing CSV sales data into a data warehouse every night for analysis.
These pipelines handle data the moment it’s created, allowing for instant analysis and quick decision-making. They’re ideal for situations like fraud detection, real-time user tracking, or IoT monitoring, where having immediate insights makes all the difference.
Example: Monitoring credit card transactions in real time to detect suspicious activities.
These pipelines are designed to run fully in cloud environments, automatically scaling with data volume and providing flexibility for modern data needs. They support both batch and real-time processing while reducing infrastructure management overhead.
Example: Using Google Cloud Dataflow or AWS Glue to handle data movement and transformation across your cloud storage and analytics tools.
Data pipeline architecture refers to the structured design of how data moves from its source to its final destination for analysis or storage. It typically includes three core stages:
Data pipelines work by collecting data from multiple sources, transforming it for consistency, and sending it to storage or analytics tools for insights.
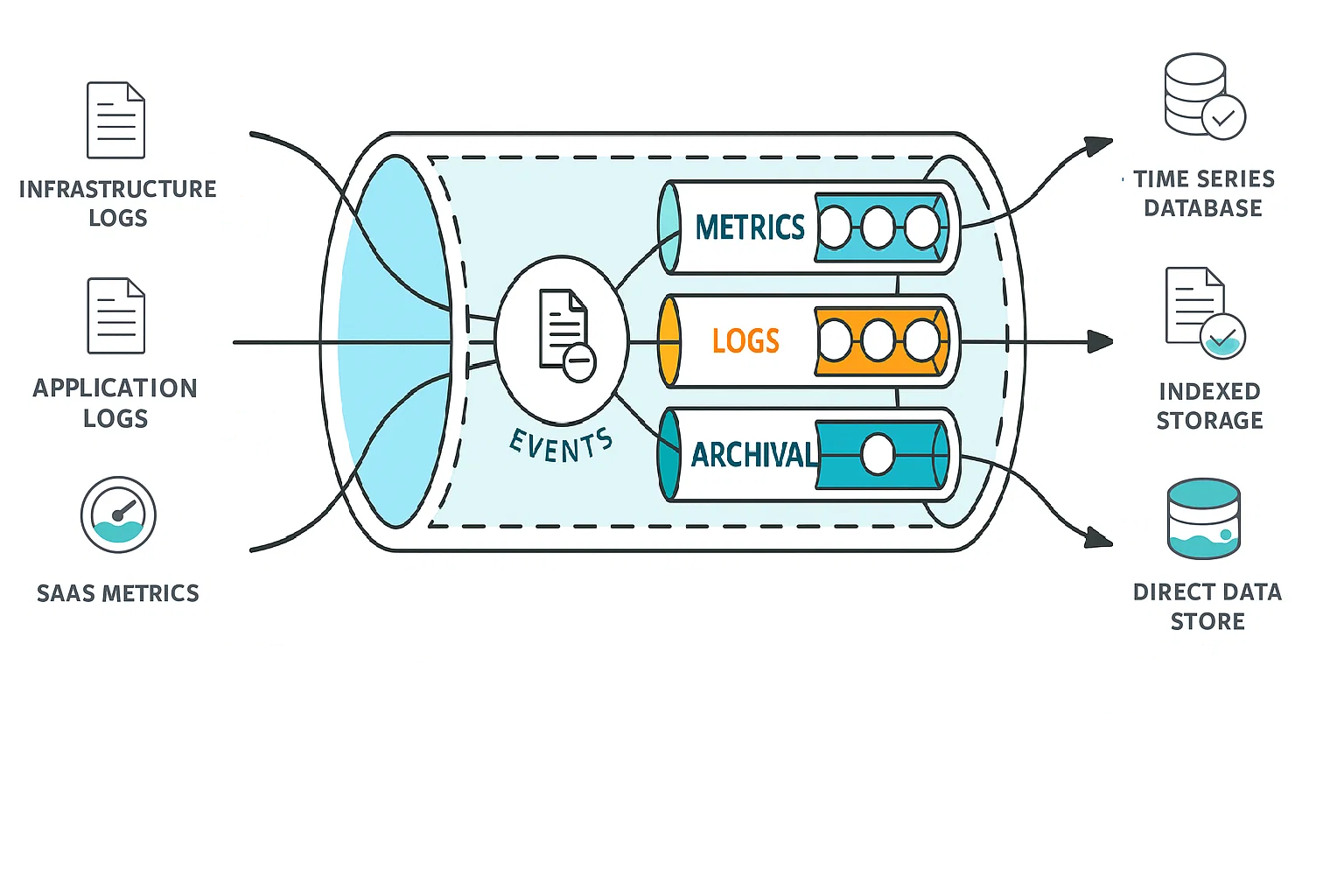
As shown in the image:
Here are four reliable data pipeline tools to help automate, manage, and scale your data workflows:
An open-source workflow management tool for orchestrating and scheduling pipelines, making it easier to manage complex ETL processes visually and systematically.
A serverless ETL service that automates data discovery, preparation, and transformation, integrating seamlessly with AWS data lakes and analytics services.
A fully managed pipeline tool that automates data extraction and loading from multiple sources into your data warehouse with minimal setup, ensuring your data stays updated.
While known for data visualization, Power BI also supports deployment pipeline basics functionalities, allowing you to connect to various data sources, perform data transformations using Power Query, and automate data refreshes for continuous insights.
Decide where your data will come from, such as databases, cloud storage, APIs, or flat files. This ensures you know what data you need to collect for your pipeline.
Clarify what data you need, the formats, and the frequency of data collection. This helps in planning how to process and structure the data.
Plan how you will clean, filter, and structure the data to make it usable for analysis. This could include removing duplicates, handling missing values, and converting formats.
Select where the processed data will be stored, such as a data warehouse, data lake, or an analytics tool, ensuring it aligns with your analysis and reporting needs.
Use scheduling tools or pipeline orchestration frameworks to automate and manage the data flow, ensuring each step runs in the correct order.
Establish monitoring to track the pipeline’s performance and catch issues like failures or delays. This ensures your pipeline delivers reliable and consistent data.
Run tests to ensure the pipeline is working correctly, data is processed accurately, and performance is efficient. Continuously optimize to handle increasing data loads and evolving business needs.



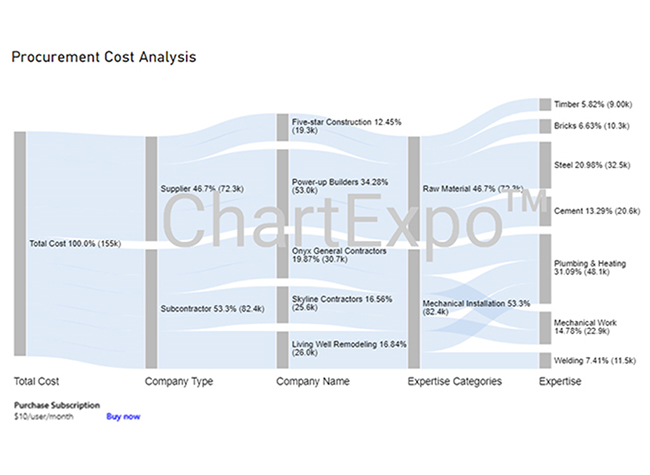
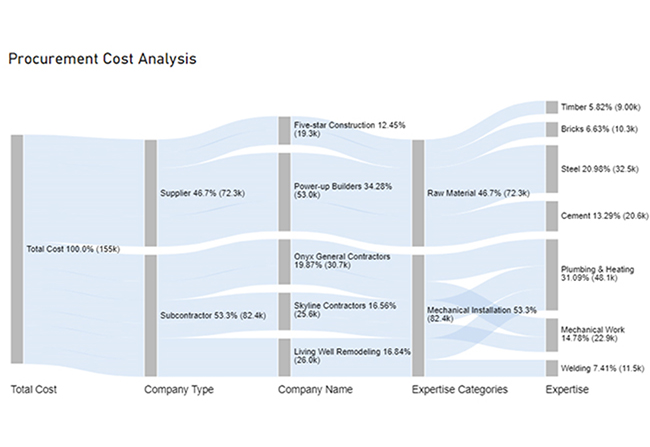
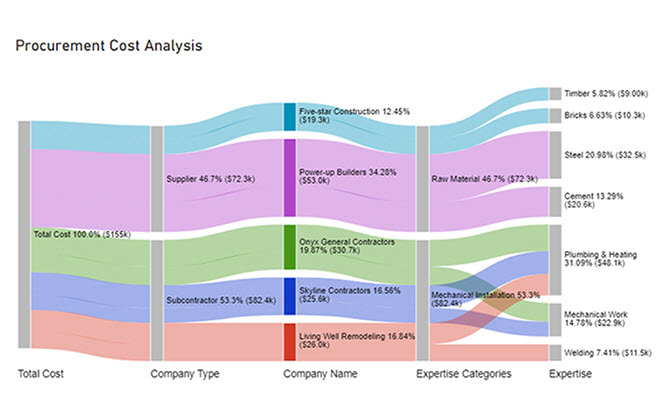
| Total Cost | Company Type | Company Name | Expertise Categories | Expertise | Cost |
| Total Cost | Subcontractor | Skyline Contractors | Mechanical Installation | Plumbing & Heating | 15456 |
| Total Cost | Subcontractor | Skyline Contractors | Mechanical Installation | Mechanical Work | 10159 |
| Total Cost | Subcontractor | Onyx General Contractors | Mechanical Installation | Plumbing & Heating | 18045 |
| Total Cost | Subcontractor | Onyx General Contractors | Mechanical Installation | Mechanical Work | 12695 |
| Total Cost | Subcontractor | Living Well Remodeling | Mechanical Installation | Plumbing & Heating | 14589 |
| Total Cost | Subcontractor | Living Well Remodeling | Mechanical Installation | Welding | 11456 |
| Total Cost | Supplier | Power-up Builders | Raw Material | Cement | 20561 |
| Total Cost | Supplier | Power-up Builders | Raw Material | Steel | 32456 |
| Total Cost | Supplier | Five-star Construction | Raw Material | Bricks | 10253 |
| Total Cost | Supplier | Five-star Construction | Raw Material | Timber | 9000 |

A data pipeline is a broader term referring to the automated flow of data from one system to another, including processes like data collection, movement, and storage for various uses such as analytics, machine learning, or reporting.
In contrast, an ETL (Extract, Transform, Load) pipeline is a specific type of data pipeline focused on extracting data from source systems, transforming it into a suitable format, and loading it into a target system like a data warehouse for analysis.
Simply put, while all ETL pipelines are data pipelines, not all data pipelines are ETL pipelines, as managing data pipelines can also include real-time streaming, data replication, or data cleaning tasks without transformation steps.
Data pipelines offer several advantages that help businesses manage and utilize data effectively:
Building data pipelines can bring several challenges, including:
The future of managing data pipelines is moving toward automation, real-time processing, and AI integration. As businesses handle larger and more complex data streams, pipelines will increasingly use machine learning for data quality checks and anomaly detection.
Serverless and cloud-native architectures will make pipelines more scalable and cost-efficient, while low-code tools will enable non-technical teams to build and manage pipelines easily. Overall, data pipelines will become faster, smarter, and more accessible, empowering organizations to make data-driven decisions in real time.
Data pipelines are used to automate the movement and processing of data from multiple sources to destinations like data warehouses or analytics tools. They help clean, transform, and organize data, making it ready for reporting, analysis, and business decision-making efficiently.
A basic pipeline involves the extraction of sales data from a CSV file, transforming it by calculating total revenue and loading the results into a database for analysis.
No, a data pipeline is not the same as ETL. An ETL pipeline (Extract, Transform, Load) is a specific type of data pipeline focused on extracting data from sources, transforming it, and loading it into a target system.
In contrast, a data pipeline is a broader concept that refers to any series of steps that move and process data from one system to another, which can include ETL, ELT, streaming data pipelines, and real-time data flows.
The three main stages in a data pipeline are:
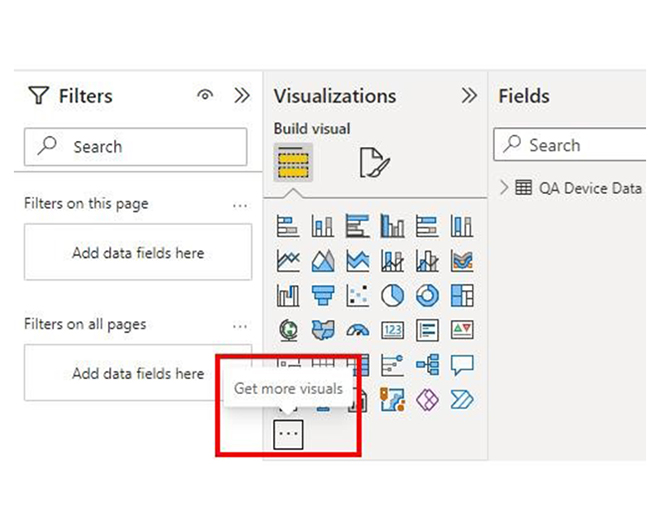
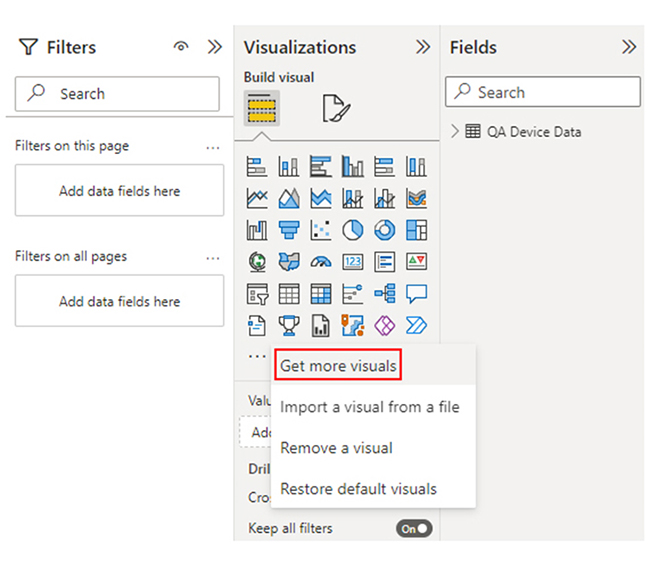
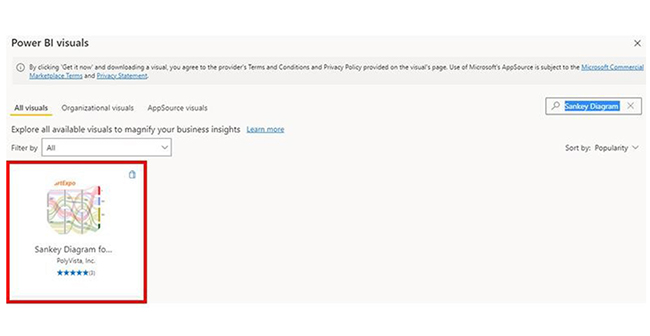
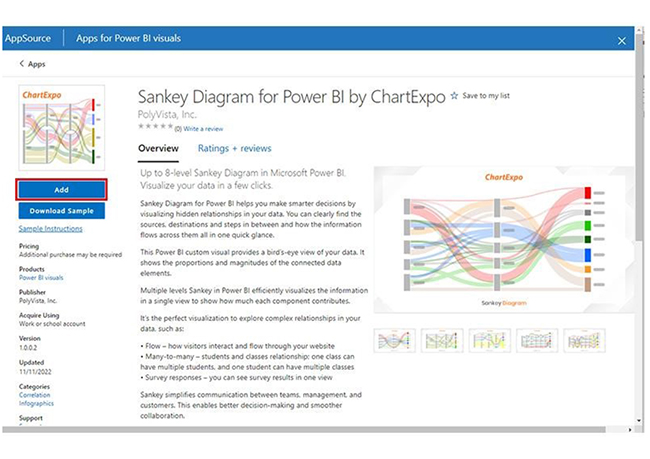
To use pipelines in Power BI:
Data pipelines help organizations automate the systematic flow of data, and it also ensure timely, accurate, and organized movement. Data pipelines can be created in Power BI using Power Query.
To get started, you have to import data from multiple sources, transform it using the Power Query Editor, apply necessary transformations, and load it into Power BI.
One major benefit of using data pipelines is the scalability and flexibility that comes with it. A data pipeline is designed to scale, and it can handle increasing volumes of data without a hitch. The scalability of data pipelines makes it almost impossible for the data infrastructure to crumble under pressure, and that allows the business to expand seamlessly.
By following the steps in this guide, you’ll be able to easily use the ChartExpo visualization tool to create compelling visuals for your business.
How much did you enjoy this article?




Calculate accounts receivable turnover ratio to measure credit collection speed, improve cash flow, and strengthen your financial strategy. Read on!

Change Management KPIs are the key to tracking adoption, performance, and ROI during transitions. Find out which metrics matter. Read on!

Data collection methods and techniques determine the quality of every insight you act on. Explore key approaches for gathering reliable data. Read on!




