Categories
What is a data lake? Is it a lake where you bring your fishing gear and catch data fish?
No – it’s not that kind of lake. A data lake is a repository for storing vast amounts of raw data in its native format. Think of it as a big, messy pond where data from different sources can swim together.



Data lakes are like a playground for data scientists and analysts. You can dive into the lake, explore the depths, and fish out the information you need.
The beauty of a data lake is that it doesn’t discriminate. It accepts all types of data, structured or unstructured, from traditional databases to social media feeds.
But beware: The data lake can quickly become a data swamp if not managed properly. Without proper governance and organization, the data can become murky and hard to navigate. Therefore, it’s essential to have a strategy in place to keep the lake clean and ensure the data stays fresh and valuable.
So, join us as we dive into the world of data lakes and explore their mysteries, challenges, and potential.
Definition: A data lake is a centralized repository that stores vast structured and unstructured data at any scale. Unlike traditional databases, it accommodates diverse data types and formats.
Organizations use data lakes to store raw, unprocessed data, enabling more flexible and comprehensive analytics. This reservoir-like storage system facilitates data exploration and analysis without predefined structures or schemas.
A Data Lake in Power BI is a centralized repository that stores large volumes of raw, structured, and unstructured data. It enables efficient data storage, processing, and analytics, allowing Power BI to access and transform vast datasets for advanced reporting and visualization.
Data lakes are essential for businesses as they provide a centralized storage system for structured and unstructured data. They enable scalability, flexibility, and cost-effective data management, allowing organizations to analyze vast datasets for insights.
With support for AI, machine learning, and real-time analytics, data lakes help businesses make data-driven decisions, improve operations, and enhance customer experiences.
You should use a data lake when your business needs to store and analyze large volumes of structured and unstructured data from multiple sources. It is ideal for organizations leveraging big data, AI, or machine learning for advanced analytics.
Data lakes are also useful when scalability, cost-effectiveness, and real-time data access are priorities, enabling better decision-making and innovation.
Data Lakes stores raw, structured, and unstructured data in its native format. They ingest data from multiple sources, organize it in a scalable repository, process it with analytics tools, and allow businesses to extract insights using platforms like Power BI.
Data lake architecture is designed to store, manage, and process large volumes of raw data from various sources. It typically consists of the following layers:
Here are the key characteristics that make data lakes a force to be reckoned with in big data.
There are four main types of data lakes based on how they are structured and managed:
Let’s explore the use cases and limitless possibilities of data lakes.
Data lakes facilitate storing and analyzing large volumes of structured and unstructured data. This facilitates comprehensive analytics and uncovering valuable insights from diverse data sources.
Data lakes complement traditional data warehouses for enhanced data storage and analytics. Integrating data lakes with data warehouses helps to store raw, unstructured data in the lake. Then, process curated data in the warehouse, optimizing cost and performance.
Data lakes play a crucial role in supporting machine learning (ML) and artificial intelligence (AI) applications. ML and AI algorithms benefit from the vast and varied datasets in data lakes. This enables more accurate model training, prediction, and decision-making.
IoT devices generate massive amounts of data. Data lakes offer a flexible and cost-effective platform to store, process, and derive actionable insights from this data.
Storing logs and event data in a data lake allows organizations to perform in-depth analysis and troubleshoot issues. Ultimately, gain visibility into system behavior and performance.
Data lakes use a variety of tools for storage, processing, integration, analytics, and governance. Power BI plays a crucial role in visualizing and analyzing data stored in data lakes.
Before you begin, ensure you have an Azure subscription, a Data Lake storage account, and a Power BI Desktop.
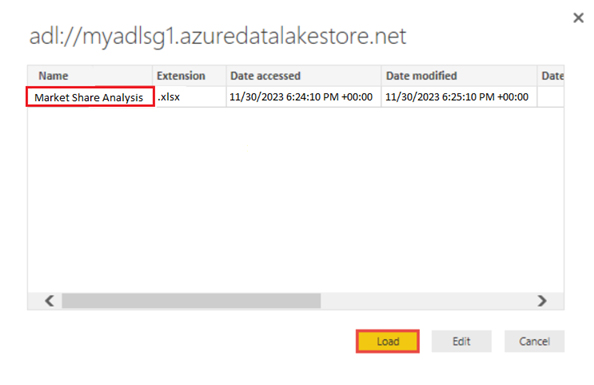
I assume you have already created a Data Lake Storage account called myadlsg1. Also, you have uploaded a sample data file (Market Share Analysis.xlsx) to it.
Follow these steps to connect with the data lake.




| Quarters | Vendors | Market Share |
| Q1 | Samsung | 27.69 |
| Q1 | Apple | 28.45 |
| Q1 | Xiaomi | 11.8 |
| Q1 | Huawei | 6.53 |
| Q1 | Oppo | 5.3 |
| Q1 | Vivo | 4.19 |
| Q2 | Samsung | 28.14 |
| Q2 | Apple | 27.58 |
| Q2 | Xiaomi | 12.62 |
| Q2 | Huawei | 6.17 |
| Q2 | Oppo | 5.5 |
| Q2 | Vivo | 4.21 |
| Q3 | Samsung | 28.45 |
| Q3 | Apple | 27.71 |
| Q3 | Xiaomi | 12.9 |
| Q3 | Huawei | 6 |
| Q3 | Oppo | 5.29 |
| Q3 | Vivo | 4.17 |
| Q4 | Samsung | 27.97 |
| Q4 | Apple | 27.62 |
| Q4 | Xiaomi | 12.68 |
| Q4 | Huawei | 5.17 |
| Q4 | Oppo | 6.07 |
| Q4 | Vivo | 4.66 |









The following video will help you with Data Lake Analysis in Microsoft Power BI.
Diving into a data lake may sound like a refreshing adventure. But don’t be fooled by the serene surface. Beneath the calm waters lie a multitude of challenges waiting to test even the bravest of data explorers.
The sheer diversity of data in a lake can lead to information overload and compromise its quality, necessitating robust governance policies. Implementing stringent data quality checks is crucial to monitor and ensure the reliability of the stored information.
Data security and privacy pose significant challenges due to the open and accessible nature of data lakes. Safeguarding sensitive information demands the implementation of encryption, access controls, and monitoring mechanisms. Adherence to security and privacy policies is essential to mitigate potential unauthorized access or data breach risks.
Efficiently managing metadata within a data lake is a pivotal challenge. Establishing effective metadata management practices is essential for facilitating seamless data discovery, comprehension, and utilization. A well-managed metadata framework enhances the overall usability of the diverse datasets stored in the lake, contributing to the success of analytics endeavors.
Data silos and fragmentation can impede collaboration and data utilization if not addressed proactively. To overcome this challenge, you need a unified data architecture. You also need robust governance practices encouraging data sharing and collaboration among different teams.
The complexity of querying and analysis arises from the sheer volume and variety of data within a lake. You should invest in powerful querying and analytics tools to streamline these processes. Also, leverage data indexing and implement data virtualization techniques for simplified access and analysis.
Scalability issues can hamper the performance and responsiveness of data lakes as the volume of stored data grows. You should ensure the data lake infrastructure can handle increasing demands. You can achieve this by planning for scalability, adopting distributed storage and processing, and leveraging cloud-based solutions.
Integrating data lakes with existing systems can be a nuanced and intricate process. Seamless integration with other data storage and processing systems is crucial to maintaining consistency and compatibility. This requires meticulous planning, strategic alignment, and a deep understanding of the existing technological landscape.
Cost management is a significant concern, especially for cloud-based data lakes. You must monitor and optimize storage, processing, and data transfer costs. Utilize cost management tools and regularly reassess infrastructure needs to ensure efficient resource allocation.
A skills and expertise Gap can hinder the effective implementation and maintenance of a data lake. To address this challenge, you should invest in training programs, hire experienced professionals, and consider external consulting services. This will help bridge skill gaps and ensure the successful management of the data lake environment.
Data lake overload is a risk associated with accumulating excessive data without a clear strategy. To mitigate this, define a concise data strategy, prioritize relevant data, and implement regular reviews and management practices. This will help ensure alignment with overarching business objectives.
Power BI integrates with Azure Data Lake to provide scalable storage and advanced analytics. Key solutions include:
The “OneDrive” is a designated data lake in Power BI. OneDrive for Business is a cloud-based storage solution that enables you to seamlessly upload, share, and access data files. This enhances collaboration and data integration capabilities within Power BI.
A data lake stores raw, unstructured data at scale, supporting diverse analytics. A data warehouse structures and organizes data for efficient querying and reporting. While data lakes handle varied datasets, data warehouses focus on structured, processed data for business intelligence and analytics.
Amazon S3, part of Amazon Web Services (AWS), is an example of a data lake. It allows organizations to store and retrieve large amounts of data flexibly. Moreover, it supports diverse data types and enables efficient analysis through various analytics and machine-learning tools.
What is a data lake?
A data lake is a flexible repository for diverse data types. It stores raw, unstructured, and structured data in a centralized pool. Unlike traditional databases, data lakes adapt to evolving data without predefined structures. Thus, they provide unparalleled agility in handling evolving and diverse data sources.
The significance of data lakes lies in their scalable infrastructure. They are capable of collecting, processing, and analyzing massive datasets. Moreover, they empower advanced analytics, machine learning, and business intelligence. Breaking down silos, data lakes provide a holistic view of the data landscape, fostering collaboration and comprehensive insights.
However, successfully implementing a data lake demands thoughtful consideration of various challenges. Data governance is critical to maintaining the stored data’s quality, privacy, and integrity. Robust governance policies, metadata management practices, and security measures help ensure the effectiveness of a data lake.
Ultimately, data lakes propel organizations toward a data-driven future. They facilitate the extraction of actionable insights from vast datasets. Embrace them to navigate and harness the potential of vast information reservoirs.
How much did you enjoy this article?




Discover diverse and high-quality Power BI report examples for inspiration and insights. Elevate your reporting with strategic visualization techniques.

A Customer Relationship Management Dashboard centralizes data, tracks key metrics, and drives smarter business decisions. Discover now!

Explore Healthcare Dashboard Examples and learn how to turn complex healthcare data into clear, actionable insights for better decision-making.




