Categories
By ChartExpo Content Team
Confirmation bias is like looking through a keyhole. You see part of the picture—usually the part that matches what you already believe.
This bias creeps into graphs, charts, and all kinds of visuals, subtly influencing decisions. You might think you’re viewing the data objectively, but confirmation bias can shape what you notice and what you ignore. Suddenly, data that doesn’t fit your narrative fades into the background.
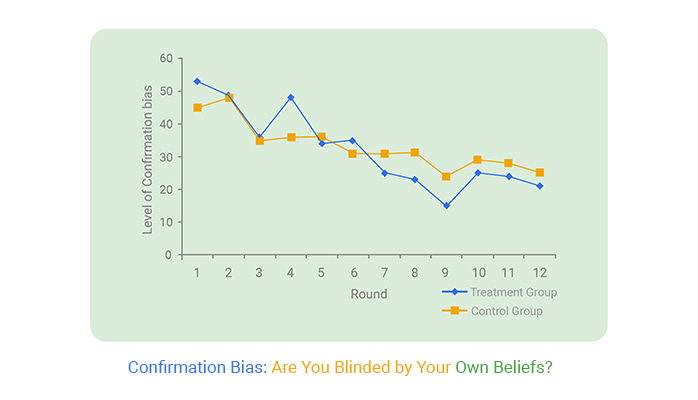


Confirmation bias isn’t just a personal quirk. It can lead entire teams down the wrong path. Think about it: a group spots trends in data that reinforce their strategies while overlooking evidence that challenges them. It feels easier, even comfortable, to stick with what’s familiar, but confirmation bias often blocks new insights and limits growth.
Breaking free from this trap starts with awareness. Recognizing confirmation bias allows you to take a step back and look at data with a more balanced eye. Instead of jumping to conclusions, you can start asking questions, digging deeper, and seeing the full story. Ready to rethink the way you interpret data? Let’s look at how to spot this bias and make more objective decisions.
First…
Imagine looking at a graph and thinking, “This proves my point!” That’s confirmation bias. It’s when people favor information that confirms their beliefs or hypotheses, regardless of whether the information is true. In data visuals, this bias can make you see what you want to see, not what’s actually presented.
Think about a sales dashboard. If you believe a new strategy is working, you might focus on data that supports this, ignoring data suggesting otherwise. This selective attention can lead to misguided decisions because you’re trapped in your belief bubble, not seeing the full picture.
It’s tricky, isn’t it? Confirmation bias in dashboards is like a silent whisper, not easy to catch. Why? Because it blends into your regular data review processes. When you pull up your business graphs and charts, your brain automatically searches for patterns that fit your predictions or hopes. This natural shortcut can skew insights, impacting the accuracy of predictive analytics and decision-making.
Moreover, dashboards often show simplified data. This simplification is great for quick decisions but bad for depth. It can strip away the context that might reveal the full story, making it easier for confirmation bias to sneak in. You see the numbers going up, and you think, “Great, our approach is working,” but what if important, contradicting data is not displayed?
In both cases, awareness is your ally. Knowing that confirmation bias exists and understanding how it can warp your data interpretation is the first step in combating it. Keep questioning what you see. Are you interpreting the data as it is, or as you wish it to be?
Confirmation bias rooted deep in our psychology. Humans prefer consistency in their beliefs and views, which makes us seek out and favor information that confirms what we already think. This bias isn’t just a harmless quirk; it shapes how we gather and interpret information, often without us even realizing it.
When numbers and data get involved, you’d think we’d be more objective, right? Not quite. Confirmation bias sneaks into analytics too.
Analysts might unknowingly select data that supports their hypothesis and ignore what doesn’t. It’s not about being dishonest; it’s human nature. Our brains are wired to look for patterns and connections, so when we think we see a trend, we tend to run with it without stopping to question if we’re only seeing part of the picture.
In the business world, decisions based on data are daily bread. But cognitive biases can twist data interpretation, leading to less-than-optimal business decisions.
For example, a marketer might interpret customer data in a way that supports a favored campaign, overlooking signs that it’s not working. This bias can cost businesses money and opportunities unless checked by rigorous methods and diverse perspectives.
One common pitfall in creating infographics is the use of misleading labels and titles that can trigger confirmation bias. This happens when the title or label of a chart or graphic supports what viewers already believe, making them less critical of the data.
For instance, a graph titled “Most People Love Chocolate” will likely lead chocolate fans to agree without scrutinizing the data presentation.
To avoid this, titles should be neutral and reflect the data accurately without suggesting a desired interpretation. A more neutral title for the same data might be “Public Preferences on Chocolate,” which doesn’t suggest a majority opinion either way and invites viewers to look at the data themselves.
Biased titles in data visuals are not always easy to spot, especially if they subtly align with common opinions or beliefs. To identify these, look for titles that seem to make a claim or directly state an opinion.
For example, a graph titled “The Best Smartphone Brand on the Market” already suggests superiority before you even view the data.
A good practice is to ask yourself if the title leads you to a conclusion without examining the underlying data. If the answer is yes, the title may be biased.
Creating neutral labels for data visuals is key to providing clear, unbiased information. Labels should describe the data or category simply and directly, such as “Age Group” or “Annual Revenue” instead of more loaded terms like “Young Consumers” or “Profitable Companies.”
Neutral labels help maintain the objectivity of the infographic and ensure that all viewers, regardless of their pre-existing beliefs or knowledge, receive the same information.
When you pick colors for your infographics, you might not realize how much they affect the message. Colors can sway opinions without us even noticing, leading to confirmation bias. This happens when the color choice aligns with the viewer’s pre-existing beliefs, reinforcing their opinions regardless of the data presented.
To avoid this, use neutral colors that don’t carry strong associations. For example, instead of using red for negative trends, which could suggest danger or stop, you might choose a softer palette like blues or greens. These colors are less likely to trigger specific biases, helping your audience focus on the information rather than the emotion.
It’s easy to unintentionally guide your audience’s emotions and decisions with color. For instance, green often implies ‘good’ and red ‘bad.’ But what if your data isn’t that straightforward? Using these colors can mislead viewers, making them see what they expect rather than what is.
To combat this, test your color schemes with various audiences before finalizing your infographic. This step can reveal unintended biases and help you adjust your palette to better convey the true story behind your data.
Creating a balanced color palette is key to fair data representation. Start by choosing colors that enhance clarity and avoid misleading your audience. You can achieve this by using a limited color scheme—too many colors can confuse and distract.
Colors aren’t the only way to represent data. Patterns and textures can be effective alternatives, especially in areas where color might not be as effective. Stripes, dots, and checks can differentiate data without suggesting any emotional bias.
Using these elements, you can present your data in a way that communicates the facts clearly without the risk of color-associated biases. Just ensure that the patterns and textures are not too busy or overwhelming, as this can detract from the data itself.
Cherry-picking data is like picking only the ripest cherries from a tree: it shows only what looks best. This practice occurs when people select data that supports their views, ignoring what doesn’t.
Imagine you’re convinced that your favorite brand makes the fastest cars. You might highlight speed tests that your brand wins but ignore the ones it doesn’t. In infographics, this can mislead viewers, presenting a skewed view of reality.
Spotting cherry-picked data in dashboards isn’t always easy, but some clues can help.
First, look for data that seems too good to be true—like a graph showing perfect progress without any dips.
Next, check the data sources. Are they credible, or do they all come from the same biased source? Also, see if important data seems missing. If a dashboard about car safety doesn’t include crash test results, something might be off.
These signs suggest that the dashboard might be showing a selective picture.
Building a transparent data inclusion process starts with setting clear rules. Everyone should know what data must be included and why. Start by defining what relevant data looks like. Make these criteria as specific as possible.
Then, involve multiple people in the data selection process. This reduces the chance of individual bias. Finally, keep detailed records of how and why each piece of data was included. This documentation makes the process clear and open to review.
Preventing cherry-picking bias requires both the right tools and the right mindset. Software that automates data collection can help. It gathers data based on pre-set criteria, reducing the chance for selective choice.
Techniques like blind analysis, where the data’s context is hidden from the analyzer, can also prevent bias. Training is crucial too. Teach team members about the risks of cherry-picking and how to avoid it. Encourage a culture of honesty and transparency in data handling. This mindset, combined with robust tools, can guard against biased data selection.
Have you ever looked at a graph and felt something was off? That’s often due to scaling manipulations, a sneaky tactic used to distort data. This method plays into confirmation bias, where data appears to support specific beliefs simply because of how it’s presented.
By stretching or compressing the Y-axis, a graph can drastically change how the information is interpreted. This manipulation can make small differences look huge or minimize significant changes, misleading viewers and feeding into pre-existing biases.
Manipulating the Y-axis is a common trick in visuals that can completely alter your perception of data. For instance, imagine two graphs showing economic growth over a decade. One graph stretches the Y-axis to make growth appear more dramatic.
The other uses a compressed scale, making the same growth seem trivial. These visuals can dramatically impact decisions and opinions, making it vital to scrutinize how axes are set in any data visualization.
Starting the Y-axis at zero is a golden rule for honest data visualization. Why? It provides a true representation of proportions. Breaking this rule can lead to misleading charts where variations in the data appear more dramatic than they really are.
Always check if the Y-axis starts at zero when interpreting a graph, and if you’re creating one, stick to this guideline to maintain integrity in your visuals.
Aspect ratio, the relationship between the height and width of a graph, plays a crucial role in how we perceive data. An incorrect ratio can distort data, making trends seem steeper or flatter than they are.
This unintentional distortion affects decision-making and opinions based on visual data. It’s essential to choose an aspect ratio that represents the data accurately, ensuring that viewers receive a true picture of the trends and changes.
Think about when you pick a movie based on reviews. You often look for opinions that echo your tastes, right? Confirmation bias in data aggregation works similarly but can be sneakier and more impactful.
It occurs when data is collected or highlighted in a way that unintentionally—or sometimes intentionally—supports pre-existing beliefs or hypotheses. This bias can distort the real story the data is meant to tell, leading to decisions or conclusions that aren’t based on an objective overview of the information available.
Aggregation bias is a tricky player in the field of data analysis. It pops up when the method used to group data points can lead to misleading conclusions.
For instance, averaging income in diverse economic regions might mask the reality of income inequality. By lumping different entities into a single category, important nuances and variations are lost, potentially leading decision-makers astray.
When it comes to displaying data, both aggregated and raw forms have their places. Best practices suggest using raw data to provide transparency and allow detailed scrutiny when accuracy is critical.
Aggregated data, on the other hand, is excellent for high-level trends and patterns that can guide data-driven decisions. The key is balance; provide enough raw data to verify the aggregates and enough aggregation to clarify complex raw data.
Distribution plots are fantastic tools for unmasking the secrets within your data. They help you see the shape of your data distribution—like identifying if your data is skewed, has outliers, or if there are peaks that suggest multiple groups within your dataset.
By visualizing these aspects, you’re better equipped to understand the full story, ensuring that important patterns don’t go unnoticed and improving the quality of the insights derived from the data.
When you skip outliers in your data, you might be playing into confirmation bias. This means you’re likely only seeing what you expect to see, missing out on what those unusual points could tell you. It’s like ignoring a piece of a puzzle; without it, the picture is incomplete. Outliers can show hidden truths or errors that need attention. By paying attention to these points, you might find new insights or spot mistakes that could lead your analysis astray.
Think of outliers as the spice in a dish. Just as a pinch of salt can change the taste, a single outlier can alter your understanding of trends.
In data visualization, outliers aren’t just noise; they can signal crucial shifts or exceptions that could lead to innovative strategies or solutions. They challenge the norm and can lead to a deeper understanding of the data set. By analyzing these points, you might uncover hidden insights that would otherwise be overlooked.
Handling outliers is a delicate balance. You want to acknowledge their presence without letting them skew the overall data story.
One approach is to use robust statistical methods that are not sensitive to outliers, like median or quantile regression.
Another method is visualizing them in a separate panel beside your main plot, so the story isn’t distorted but the outliers are still in clear view. This way, you keep the integrity of your main data story while acknowledging the exceptions.
The following video will help you create a Box and Whisker Plot in Microsoft Excel.


The following video will help you to create a Box and Whisker Plot in Google Sheets.
When you’re diving into data visualization, picking the right chart is more than just an aesthetic choice; it’s a decision that can shape how your audience interprets the data. Confirmation bias sneaks in when the chart type confirms pre-existing beliefs, rather than presenting an unbiased view.
For instance, donut charts are great for showing parts of a whole but can be misleading if used to show changes over time, possibly reinforcing incorrect assumptions.
Bar charts are a go-to for many due to their straightforward style. However, their simplicity can backfire.
For example, using a bar chart to represent continuous data can lead to misinterpretation of the trends and relationships between variables. It’s vital to question whether the simplicity of a bar chart might lead the audience to overlook complex dynamics in the data.
Line and scatter charts can be allies in your quest to present data more effectively. Line charts show trends over time, making them excellent for observing the rise and fall of values and helping bypass confirmation bias by laying out temporal relationships plainly. Scatter charts, showing the relationship between two variables, can reveal correlations without suggesting causation.
Don’t stick to one chart type when exploring or presenting data. Cross-checking insights with multiple chart types can illuminate different aspects of the data and help avoid the pitfalls of confirmation bias.
If a bar chart suggests a trend, verify it with a line chart. If a pie chart shows a dominant segment, look at the same data in an analysis of Scatter Plots to check for underlying patterns or outliers. This approach not only provides a fuller picture but also engages your audience with a richer, more informative narrative.
When you group data, confirmation bias might sneak in. This happens when you pick binning methods that support your initial beliefs, ignoring other data patterns. It’s like when you hear only what you want to hear in a conversation! To avoid this, question your choices and seek input from others who might see things differently.
The way you bin data can shape how others see it. If bins are too wide, important details might get lost. If they’re too narrow, you might see patterns that aren’t really there. It’s a bit like looking through a camera lens. The zoom level can really change what you focus on!
To find the best bin width, you can use methods like the Freedman-Diaconis rule. This method uses data spread (max-min) and the number of data points to suggest a width. It’s like adjusting your steps to avoid stepping on cracks in the sidewalk. Not too big, not too small—just right!
Why not try a few different ways to bin your data and compare them? It’s like trying on several pairs of glasses to see which gives you the clearest vision. Visualizing data with different bins can show you how your initial choice might lead you astray. Always check your blind spots!
When analyzing data, it’s easy to slip into the trap of confirmation bias, especially when selecting comparison groups. This happens when groups are chosen based on expectations or desires about the outcome rather than objective criteria. This skew in group selection can lead to results that reinforce pre-existing beliefs, inadvertently “stacking the deck” in favor of these expectations.
To steer clear of confirmation bias in benchmark comparisons, begin by setting clear, unbiased criteria for the selection of comparison groups before you collect or analyze your data. Stick strictly to these criteria, regardless of the data outcomes you anticipate or desire.
This approach ensures that the selection process remains objective and that the results are valid and reliable.
One effective method to maintain objectivity in selecting comparison groups is through automation. By using software or algorithms to select peer groups based on predefined, impartial criteria, you remove personal bias from the equation. Automation helps in consistently applying the same standards across all data sets, leading to more accurate and trustworthy analyses.
Randomized sampling is another robust technique for ensuring fairness in data comparisons. By randomly selecting which data points or subjects to include in each group, you minimize the risk of sampling bias.
This method is particularly useful in experimental designs or when large data sets are involved, as it guarantees that each subject or data point has an equal chance of being chosen, keeping the comparison groups balanced and unbiased.
When creating infographics, designers must avoid swaying the audience subtly through confirmation bias. To strike a balance, it’s vital to present data neutrally, allowing the information to speak for itself without directing the viewer to a predetermined conclusion. By doing so, we uphold the integrity of the data and foster a more informed audience.
Infographics that cram too much data into a small space can overwhelm rather than inform. Visual overload happens when the viewer cannot discern the key points amidst a sea of numbers and texts. The goal should be clarity, not density.
Simplifying visuals without omitting critical information ensures that viewers can grasp the intended message quickly and clearly, enhancing comprehension and retention.
While simplifying data is crucial, over-simplification can be just as harmful as visual overload. Stripping away too many details might lead to misinterpretation or a loss of essential nuances.
A well-designed infographic communicates the main findings while also hinting at the complexity that underlies the data. This approach respects the intelligence of the audience and encourages further inquiry and analysis.
Interactive visualizations are a fantastic tool for engaging viewers by letting them dig deeper into the data at their own pace. By interacting with the data, users can uncover more layers of information, which enriches their understanding and engagement.
This method empowers the viewer, turning passive observation into an active exploration. It’s not just about seeing the data but experiencing it.
Have you ever found yourself nodding along to a set of data that just confirms what you already believed? That’s confirmation bias at play, and it’s a sneaky beast, especially when we rely too heavily on aggregated metrics.
These metrics and KPIs, like averages or totals, can blind us to the real story. When we only see the summarized data, we miss out on the nuances and potentially contradictory information that could challenge our preconceived notions or lead us to new insights.
By just looking at these broad numbers, we might continue to make decisions or carry beliefs that are supported by general data but contradicted by the hidden specifics.
Averages are great for quick summaries, right? But they can also mislead us big time. Imagine you’re looking at the average sales data from different regions. All might seem well until you realize that one region’s extremely high sales skew the average, masking poor performance in multiple other regions.
This is a classic case of hidden variations not apparent in the average. These variations are critical because they hold the secrets to true performance insights, challenges, and opportunities that a simple average just glosses over.
Distribution charts are like the superheroes of data visualization. They swoop in to save the day when aggregated metrics fall short. By showing how data points are spread across a range, these charts reveal the shape of the data.
Is it skewed? Is it uniform? You won’t know this from an average, but a distribution chart lays it all out. They’re perfect for spotting outliers, understanding variability, and getting a fuller picture of what’s really going on with your data.
Next time you’re presented with an average, why not pair it with a distribution chart and watch the hidden stories emerge?
Have you ever stared at an infographic and felt more confused than when you started? It’s not just you. Sometimes, designers pile on too many details to hide their biases.
This tactic can lead to confirmation bias, where the viewer only sees what they want to see, supported by the overly complex visuals. Think about it: when a graph throws too much at you, aren’t you likely to just focus on what feels familiar and ignore the rest? That’s confirmation bias in action, and it’s a real problem when clarity is essential.
Data dashboards are meant to simplify our understanding of statistics. But what happens when they do the opposite? Adding too many widgets, dials, and controls can distract and even mislead users.
It’s like when a dashboard lights up like a Christmas tree with warning signals; it’s hard to know where to look first! This overcomplication can make it tough to get a clear, quick insight. Instead, users spend more time figuring out the dashboard than the data.
Simplifying doesn’t mean dumbing down. It means making information accessible. Think of it as decluttering a crowded room so you can finally see the beautiful furniture!
In terms of visuals, it’s about focusing on the key points without losing the message’s depth. For instance, use bold colors to highlight major trends and keep the text minimal but meaningful. This way, viewers can grasp the complex data without feeling overwhelmed.
Confirmation bias in data visualization happens when you interpret or highlight data in a way that fits your existing beliefs. It’s when you see what you want to see in a chart, not necessarily what the data actually shows. This bias can influence decisions and strategies, leading to skewed conclusions. For example, if you’re convinced that a marketing campaign is successful, you might only focus on charts that show positive results, ignoring data that suggests otherwise. To avoid this trap, it’s crucial to approach data with an open mind and consider all the evidence, not just the parts that confirm your beliefs.
Confirmation bias can be harmful because it distorts the truth. When you only pay attention to data that supports your ideas, you risk missing critical insights that might lead to better decisions. For businesses, this can mean investing time and resources in the wrong projects, campaigns, or strategies. By letting confirmation bias shape your analysis, you create a feedback loop where only favorable results are noticed, while potential problems or opportunities get overlooked. In the long run, this can hurt your company’s performance and growth.
Some common traps include cherry-picking data, using misleading chart titles, or adjusting axes to exaggerate trends. Cherry-picking involves selecting only the data that supports your viewpoint while ignoring contradictory evidence. Misleading titles can set the stage for biased interpretations before the viewer even looks at the data. Adjusting axes—like stretching the Y-axis—can make changes seem more dramatic than they are. These tactics might not be intentional, but they can still steer the audience toward a biased conclusion. Always double-check your visualizations to ensure they represent the full picture.
To combat confirmation bias, start by being aware that it exists. Approach your data analysis like a detective, looking for evidence both for and against your assumptions. Use multiple chart types to cross-check your findings. For example, if a bar chart shows a trend, verify it with a scatter plot. Involve diverse perspectives when reviewing data to catch biases you might miss. Lastly, regularly audit your visualizations for neutrality, ensuring that titles, colors, and labels are objective and not leading.
Analysts are human too, which means they’re susceptible to biases like everyone else. Often, they face pressure to deliver results that align with business goals or expectations, which can unconsciously influence the data they choose to focus on. Additionally, when an analyst has invested a lot of time into a project, they might be more inclined to see what they hope to find. This is why it’s essential to have systems in place that encourage objectivity, such as peer reviews and transparent reporting practices.
Unfortunately, it’s nearly impossible to eliminate confirmation bias entirely because it’s part of how our brains work. However, you can reduce its impact by being vigilant and proactive. Always question your interpretations and seek out contradictory evidence. Use tools and techniques, like randomized sampling or blind data analysis, to reduce the influence of your expectations. Remember, the goal isn’t perfection but rather a balanced and accurate understanding of the data.
Confirmation bias sneaks into data visualization in ways you might not even notice. It happens when you unconsciously favor data that supports what you already believe and ignore what doesn’t. This can lead to poor decisions that impact your business, strategy, or even public policy.
By staying aware of this tendency, you can create visuals that present data objectively. Start by questioning your assumptions and letting the data guide your story, not the other way around. Embrace diverse viewpoints and review your visualizations through a critical lens. This approach doesn’t just improve your charts—it builds trust in your conclusions.
Data visualization should be about revealing the truth, not just backing up what you think you already know. So, be honest, be transparent, and let the data speak for itself.
Remember: the clearer your view, the better your decisions.
How much did you enjoy this article?




Google Forms to Google Sheets keeps your data organized and current with every submission. Learn the steps, methods, and tips now!

Product survey questions reveal what customers truly think. Learn how to ask the right ones and act on the survey results. Read on!
Learn how the 5-Point Performance Rating Scale improves employee evaluations with clear, consistent, and fair performance reviews across teams.




