Categories
After gathering data, it has to undergo data cleaning, pre-processing, and wrangling. Next, you’ll have to feed it into an outstanding model and get output in probabilities. All these make up the confusion matrix.



In this guide, you’ll discover answers to the “what is a confusion matrix” question. You’ll also discover what a confusion matrix tells you, and when you should use a confusion matrix.
First…
Definition: A confusion matrix is a table used to evaluate the performance of a machine learning classification model. It helps you understand how well your model is predicting results by comparing actual outcomes with predicted ones.
Here’s what it shows:
The confusion matrix gives a clear snapshot of model accuracy, helping you spot where predictions go wrong and analyze performance especially useful when dealing with imbalanced datasets.
Here are the major reasons why a confusion matrix is essential for evaluating the performance of a classification model.
Confusion matrix offers insights into the performance of a classification model:
Let’s understand a confusion matrix with a simple example of a binary classification problem predicting whether an email is Spam or Not Spam.
| Actual / Predicted | Spam | Not Spam |
| Spam | 80 (TP) | 10 (FN) |
| Not Spam | 5 (FP) | 105 (TN) |
Explanation:
The confusion matrix is the foundation for calculating key performance metrics in classification models.
Here are the main formulas derived from it:
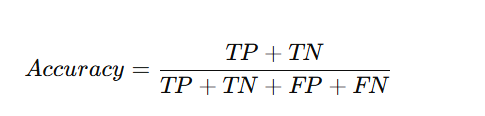
Measures how often the model makes correct predictions.
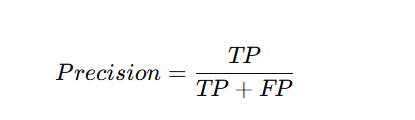
Shows how many predicted positives were actually correct.
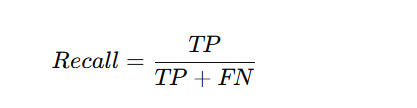
Indicates how many actual positives were correctly identified.
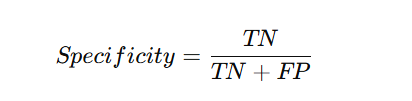
Measures how well the model identifies negative cases.
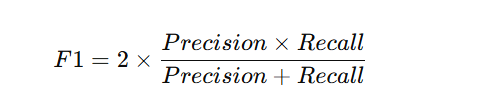
Balances precision and recall for overall performance.
Here are the steps to help you create a confusion matrix:
Compare each prediction with the actual label to categorize results:
Create a 2×2 table where:
Use the matrix values to compute performance metrics such as:
Display the confusion matrix using a heatmap or chart for better clarity.
Analyze the results to understand where the model performs well and where misclassifications occur.
A confusion matrix helps you see how accurately a classification model makes predictions by comparing actual and predicted values.
Here’s how to read it:
Here are easy ways of reading and interpreting a confusion matrix.
The confusion matrix for a binary classification problem (two classes, denoted as Positive and Negative) looks like this:

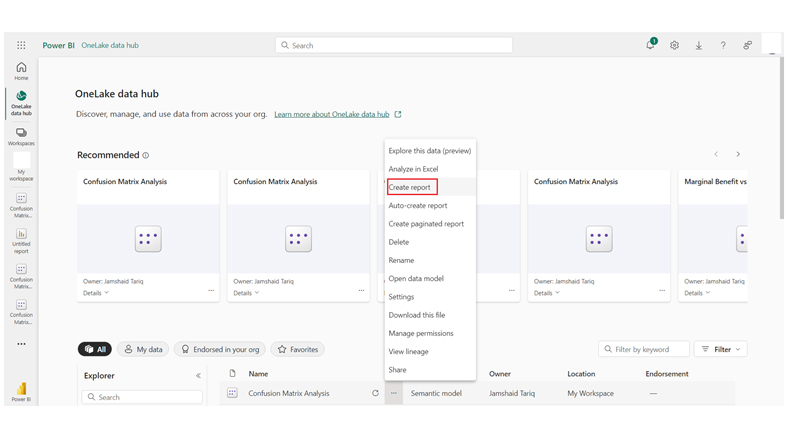
We can use the Sankey plot in Power BI to complement a confusion matrix by visualizing how data flows between predicted and actual categories, bringing in a Sankey diagram maker to streamline the setup and deliver interactive flows
Stage 1: Logging in to Power BI



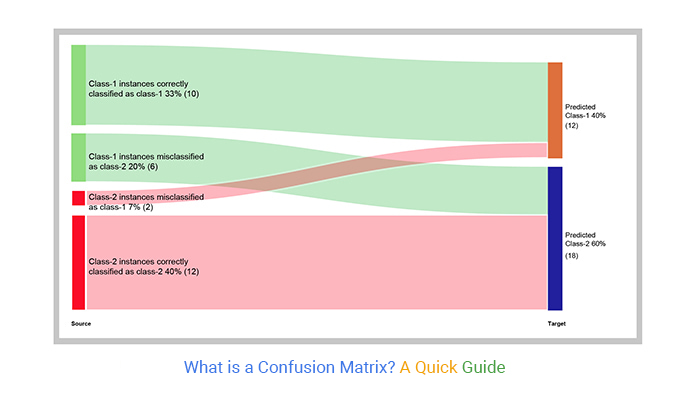
| Source | Target | Count |
| Class-1 instances correctly classified as class-1 | Predicted Class-1 | 10 |
| Class-1 instances misclassified as class-2 | Predicted Class-2 | 6 |
| Class-2 instances misclassified as class-1 | Predicted Class-1 | 2 |
| Class-2 instances correctly classified as class-2 | Predicted Class-2 | 12 |
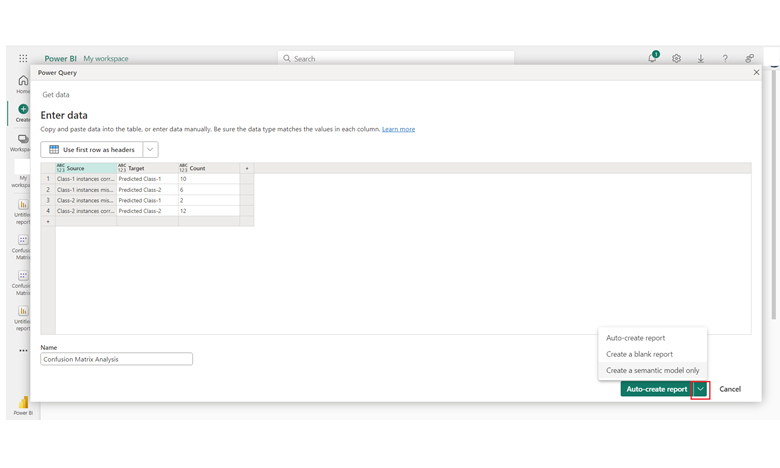
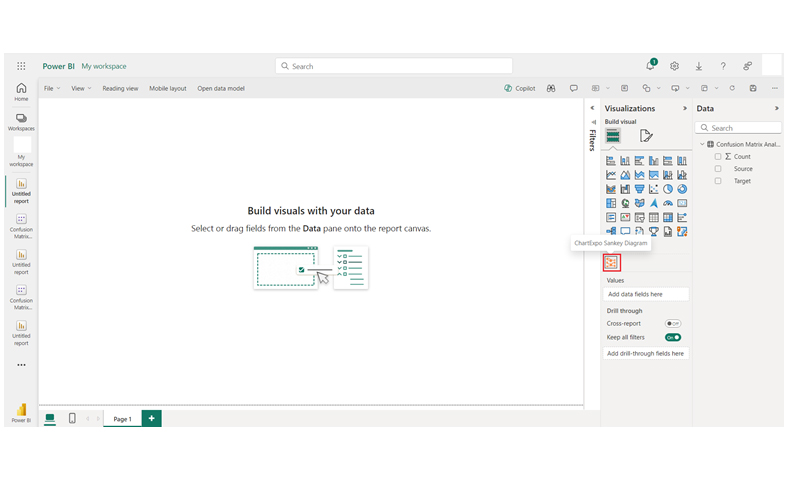
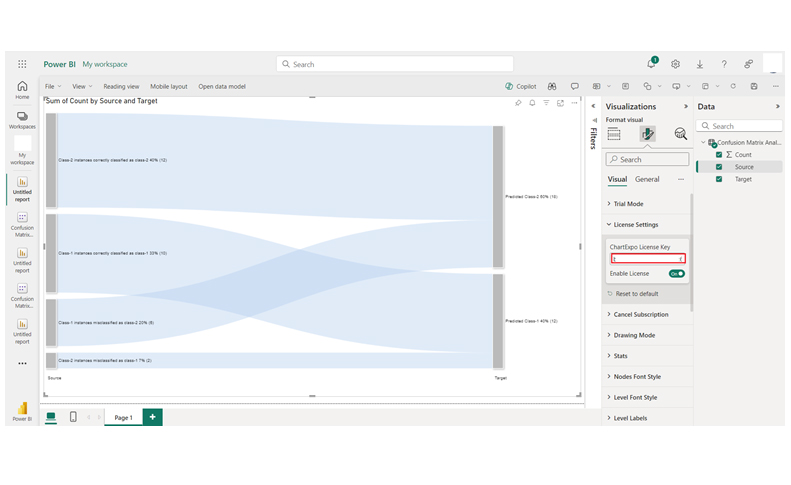
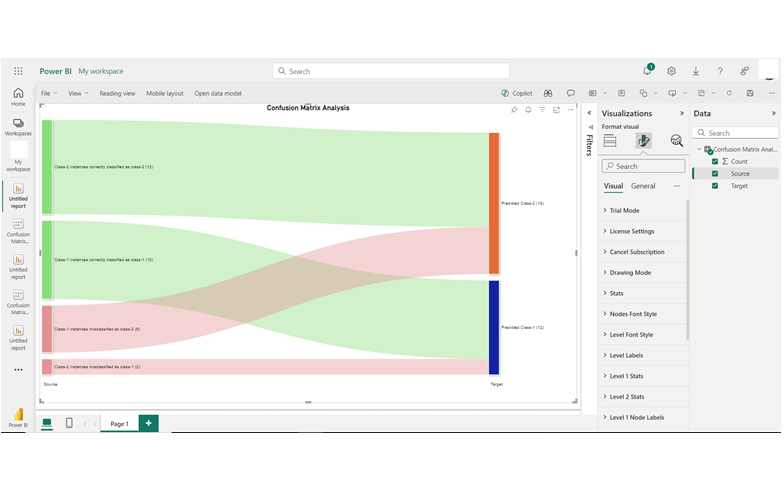
From the data, you’ll see the classification model’s performance: 10 Class-1 instances are correctly identified, while 6 are misclassified as Class-2. For Class-2, 12 instances are correctly classified, but 2 are misclassified as Class-1.
Dive into the concept of the Confusion Matrix with this interactive tutorial. This essential tool allows you to visualize the performance of classification models, highlighting key metrics like accuracy, precision, recall, and F1 score. By mastering the Confusion Matrix, you gain a deeper understanding of your model’s strengths and weaknesses, empowering you to fine-tune predictions. Using charts and graphs to represent the matrix makes it easier to identify patterns, enhance decision-making, and improve model outcomes. With a clear visual representation, the Confusion Matrix becomes an invaluable asset for optimizing machine learning processes and ensuring better, more reliable results.
Used to evaluate medical classification models, such as predicting whether a patient has a disease based on test results. Helps analyze false positives and false negatives to improve accuracy.
Helps measure how well an email filter classifies messages as Spam or Not Spam, reducing errors like marking important emails as spam.
In banking, confusion matrices are used to check how accurately models predict loan defaults or credit risk levels.
Businesses use it to assess models that predict whether a customer will stay or leave, helping reduce false predictions and improve retention strategies.
Used to evaluate models in AI systems that classify images, faces, or spoken words, showing how often the system correctly identifies different categories.
The four values in a confusion matrix are:
Type 1 error (False Positive): Predicted positive but negative.
Type 2 error (False Negative): Predicted negative but positive.
A good confusion matrix shows high values on the diagonal (True Negatives and True Positives) and low values off-diagonal (False Negatives and False Positives). All these help to indicate accurate predictions across classes.
A confusion matrix is designed to show model predictions versus the actual outcomes in a classification task. It helps in evaluating model performance and understanding errors (like false negatives/positives). It also helps in calculating metrics like recall, precision, and accuracy.
With a confusion matrix, you can easily set decision thresholds for classification inputs. Stakeholders have the option of adjusting these thresholds based on the trade-offs between different types of errors.
To analyze the confusion matrix, you’ll have to use good visuals – and that’s where tools like ChartExpo come into play.
How much did you enjoy this article?




Calculate accounts receivable turnover ratio to measure credit collection speed, improve cash flow, and strengthen your financial strategy. Read on!

Change Management KPIs are the key to tracking adoption, performance, and ROI during transitions. Find out which metrics matter. Read on!

Data collection methods and techniques determine the quality of every insight you act on. Explore key approaches for gathering reliable data. Read on!




