Categories
Knowing whether an AI model actually works requires more than intuition or anecdotal feedback. LLM evaluation metrics provide engineering and product teams with a systematic framework for measuring output quality, tracking reliability over time, and surfacing issues before they reach production environments.
From gauging the relevance of answers to checking safety compliance, these measurements convert vague impressions into verifiable, repeatable results.
Whether you are an AI engineer fine-tuning model behavior, a researcher benchmarking outputs, or a business leader making deployment decisions, structured evaluation shapes every outcome.
This guide covers the six core metrics, essential components, practical analysis steps in Google Sheets, and the strategic advantages of consistent measurement.
Definition: LLM evaluation metrics are standardized measurement methods used to assess the output quality and performance of large language models. They determine whether responses are accurate, contextually relevant, complete, and safe across a range of tasks.
These assessments cover a wide range of output categories, from question-answering and document summarization to translation and multi-turn conversation. They examine attributes such as factual consistency, coherence, and response completeness.
Applied systematically, they allow teams to compare model versions, identify performance gaps across datasets, and maintain reporting consistency.
AI engineers, researchers, compliance officers, and business leaders all rely on this structured data to validate improvements and confirm that outputs meet the standards required for real-world deployment.
Without quantifiable benchmarks, AI system quality is hard to defend or improve. LLM evaluation KPIs supply the structure teams need to validate performance systematically.
They are critical for teams that need to:
Sound LLM evaluation metrics depend on structured frameworks and well-defined standards that make assessments reproducible across different environments.
Core components include:
Dedicated tools help teams run, track, and report LLM evaluation metrics at scale, reducing manual effort and improving result consistency.
Common solutions include:
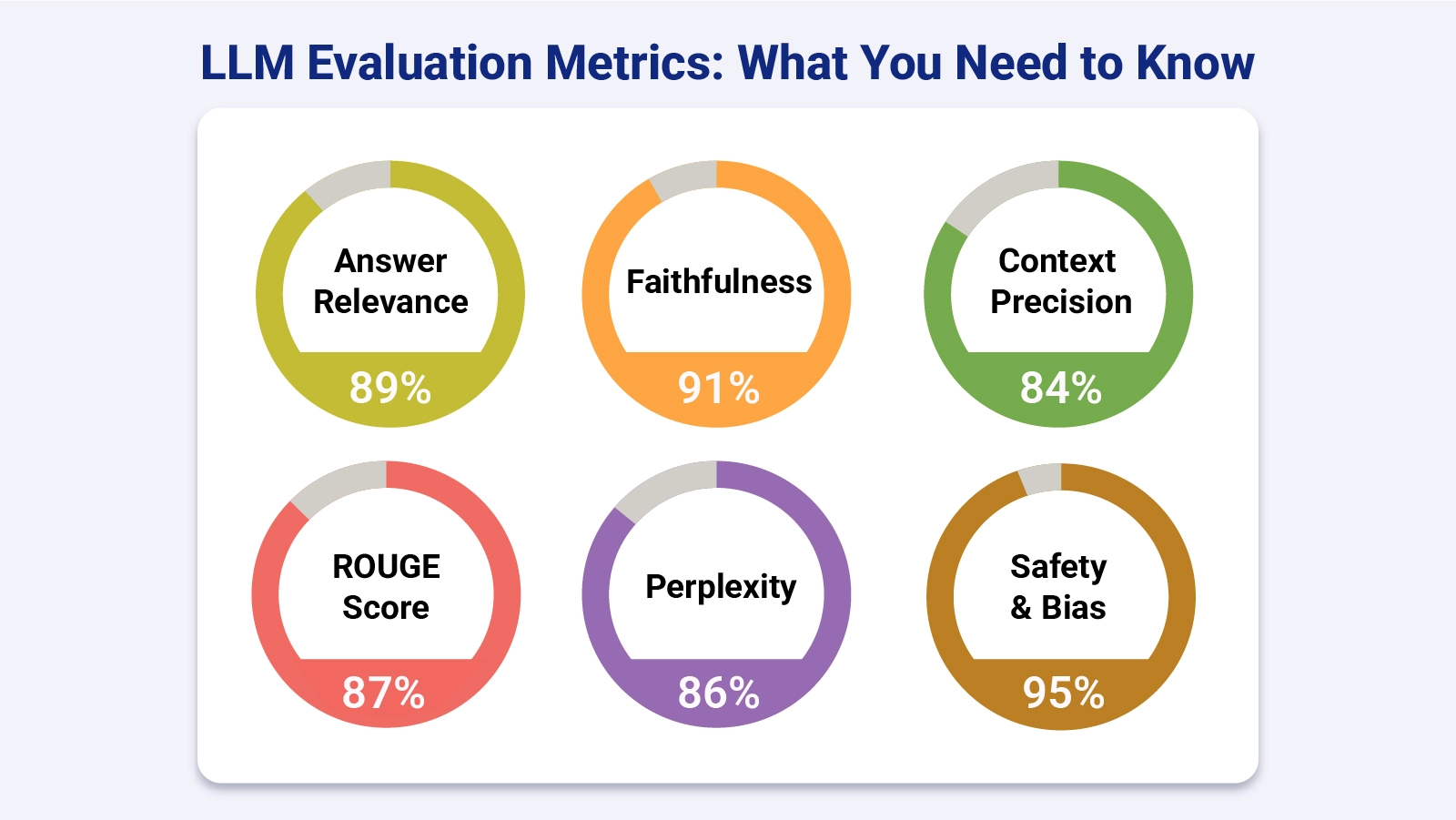
Each of the core LLM evaluation metrics below targets a distinct dimension of output quality. Together, they give teams a structured and reliable basis for assessing whether a model produces accurate, contextually grounded, and responsible outputs.
Answer relevancy gauges how directly a model’s response addresses the user’s query. It examines whether the output stays on topic, excludes unnecessary detail, and satisfies the intent behind the prompt, much as growth metrics serve as indicators of progress over time.
Faithfulness, also called groundedness, verifies that responses remain factually consistent with the source material. It is the key tool for catching hallucinations and stopping unsupported claims from entering model outputs.
This pair of measures examines how the model retrieves and applies relevant context. Precision reflects the proportion of retrieved information that was actually relevant, while recall captures whether important context was overlooked.
ROUGE and BLEU measure text similarity by comparing generated outputs against references, delivering quantifiable overlap scores much like financial metrics in structured analytical reporting.
Perplexity quantifies how well a language model predicts word sequences. A lower score signals better fluency and a stronger underlying modeling capability.
Safety and bias metrics determine whether model outputs carry harmful, toxic, or discriminatory content. They enforce compliance with ethical standards and applicable regulatory requirements.
Working with LLM evaluation KPIs in Google Sheets lets teams organize, compare, and visualize performance data efficiently. Follow these steps:
Key Insights
Putting LLM metrics into practice delivers measurable value across AI programs by strengthening governance, improving output consistency, and enabling responsible deployment decisions.
Key advantages include:
Getting the most from evaluation practices means treating them as living tools, not static snapshots. Best practices include:
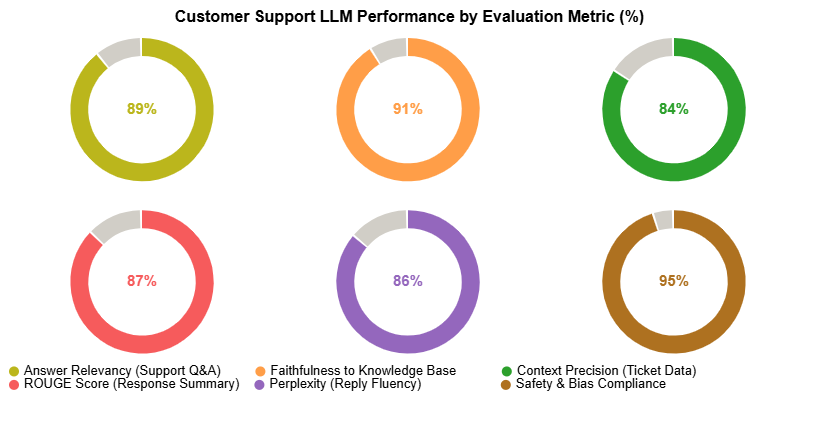
The most critical LLM evaluation metrics span answer relevancy, faithfulness, context precision and recall, perplexity, and safety measures. The appropriate combination varies by use case; customer support scenarios typically prioritize safety, while research applications place greater weight on accuracy.
Teams should measure during development, immediately following fine-tuning, and on a continuous basis throughout production to maintain stable, consistent performance.
Yes. Bias-specific evaluation approaches surface harmful or discriminatory patterns in model outputs, letting teams retrain and add safeguards before deployment.
Every AI system deployed at scale carries risk, and LLM evaluation metrics are the mechanism teams use to quantify and manage that risk.
They turn anecdotal impressions into structured evidence, expose weaknesses before users encounter them, and create a feedback loop that supports smarter model decisions across development and production.
By combining a core set of proven metrics with visualization tools, organizations gain the clarity they need to act on evaluation data rather than just collect it.
The result is a model development process that is more transparent, more defensible, and more aligned with the real-world standards that users and regulators expect.
How much did you enjoy this article?




Calculate accounts receivable turnover ratio to measure credit collection speed, improve cash flow, and strengthen your financial strategy. Read on!

Change Management KPIs are the key to tracking adoption, performance, and ROI during transitions. Find out which metrics matter. Read on!

Data collection methods and techniques determine the quality of every insight you act on. Explore key approaches for gathering reliable data. Read on!




